
Enhanced Compute Engine is a Power BI premium feature to improve the performance of Dataflows. Even though Power BI Dataflows are available without needing to be a Premium user, this capability is only available for Premium subscribers.
According to Microsoft, the enhanced compute engine has the ability to boost the performance of Power BI dataflow by up to 20 times. That sounds a lot, right? So, let us find out how Power BI Enhanced Compute Engine does that. But before we jump onto more details about Enhanced Compute Engine, let's first discuss a few essential items.
Query Folding
Query Folding pushes the heavy operations to data sources. The power query engine gets the result of those operations by 'folding' that query and sending those operations to the data sources. As a result, we get better performance and reduce load of where the query is being executed.
Dataflow Storage
We talked about Query Folding before diving deep into Enhanced Compute Engine because of the nature of Dataflow storage. For example, the Power BI dataflows store their data in CDM Folders. CDM stands for Common Data Model folders, and it is a simple folder in a data lake with CSV files for data and a Json file for metadata.
Mashup Engine
As CDM folders are simple file storage, there needs to be some compute engine or some process that can implement the logic for sorting or grouping or other transformation operations. Without the Enhanced Compute Engine, that process is the M engine (mashup engine) used by power queries everywhere.
Without the Enhanced Compute Engine, the mashup engine extracts data from CSV files, processes it in memory, and then generates whatever output is required.
Memory
We are confined to configured memory in our Power BI premium capacity when we are doing this without Enhanced Compute Engine. By default, it gives us 700 Mb worth of physical memory, which we can increase or decrease, but the default memory remains 700 Mb.
Suppose we need to work with more data beyond that limit (physical memory limit configured at the capacity level). The mashup engine then pages it out to virtual memory in that scenario. As a result, it makes use of the underlying physical storage. As you may be aware, we encounter a significant performance issue if we switch from RAM to physical memory. As an outcome, when we reach a certain data volume, some operations become noticeably slower.
Enhanced Compute Engine
This is where the Enhanced Compute Engine comes in. Enhanced Compute Engine will create a sequel-based cache of data present in those CDM folders. Now, this is worth thinking about what the data flow engine is essentially doing. It takes the data from the physically stored CSV files and loads it into a sequel instance managed by the premium capacity (power BI service).
The process above put the data into tables where the mashup engine can take advantage of query folding because that mashup engine knows the capabilities of the sequel as a storage engine and is its own compute engine. So it can take all of those expensive operations (sorting, grouping, and so on). Furthermore, it can push those down to that sequel engine, where they can be performed closer to the data source in a much more efficient way.
At this point, when one dataflow query is accessing another dataflow entity (linked and compute entity), and Enhanced Compute Engine is used, the mashup engine can push upstream all of this processing that otherwise would need to do in memory itself.
How to Setup?
As I mentioned at the beginning of this article, Enhanced Compute Engine is a Power BI premium capability. Therefore, one needs to have a premium subscription to reap the benefits of Enhanced Compute Engine. For premium users, by default, the Enhanced Compute Engine is turned on. But if it is not on, then you can follow the steps below:
- Navigate to your workspace containing the desired dataflow.
- Toggle between the three dots in front of dataflow.
- Select Settings from the drop-down menu.
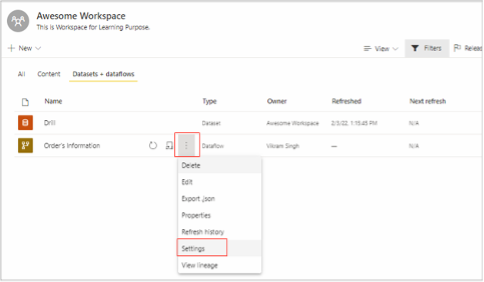
By clicking on 'Settings,' Power BI will land us on the page shown in the image below. And as you can see, there is an Enhanced Compute Engine settings pane. Expand that, select the desired option, and click on the apply button to save the selection.
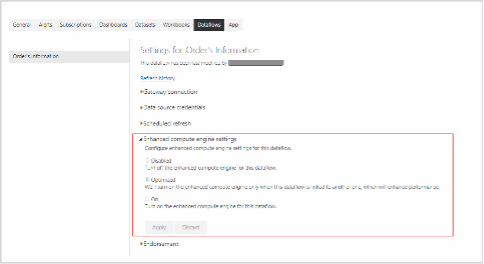
Now you might ask what the ‘Optimized’ (default) option means. With the Optimized option, the Enhanced Compute Engine is turned off. It is automatically turned on when the dataflow is connected to another dataflow. You can also check the ‘On’ option to always keep the Enhanced compute engine active.
Once this is done, Compute Engine will be used anytime you load data into your dataflow's entities. When you load the data into your underlying CDM folders, your premium capacity will also create that sequel-based cache of the dataflow entity data. From this point on, when one entity is querying another, it will be using that sequel cache as its data source.
Best use of Enhanced Compute Engine
To make the best use of Enhanced Compute Engine, you'll need to split the ETL process into two dataflows.
Dataflow 1: This dataflow should work as staging dataflow and only be ingesting all of the required data from data sources and placing it into dataflow 2.
Dataflow 2: Perform all ETL operations in this second dataflow, but make sure you're referencing Dataflow 1, which should be of the same capacity. Also, ensure you perform operations that can fold (sort, filter, group by, distinct, join) before performing any other operation to ensure the compute engine is utilized.
The fact that the Enhanced Compute Engine only operates on top of existing entities explains why we require more than one dataflows. If your dataflow refers to a data source that is not a dataflow, you will not notice any speed improvements. In addition, because the data must be sent to the Enhanced Compute Engine and in some big data scenarios the initial read from the data source will be slower.
Like what you see? Share with a friend:


